Repository Types
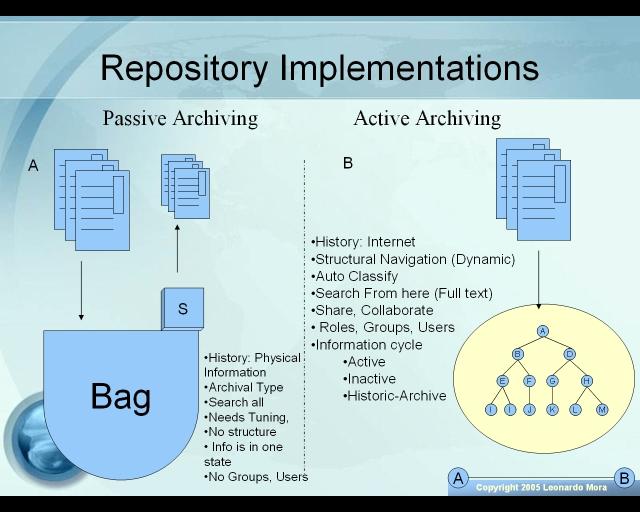 Historically and after observing the way people see things, we have on one side the Library type which I call it Passive archiving, where you have books and publications (Physical items typically)stored in a single place (Public and private libraries follow this method), and you have a single database to find the title of the book, author, genre, etc. It’s features are: Information is in archival mode usually for ever, when searching you are always searching the entire collection, information does not have a cycle, needs tuning when classifying records and it does not posses a structure. The limitations are:
Historically and after observing the way people see things, we have on one side the Library type which I call it Passive archiving, where you have books and publications (Physical items typically)stored in a single place (Public and private libraries follow this method), and you have a single database to find the title of the book, author, genre, etc. It’s features are: Information is in archival mode usually for ever, when searching you are always searching the entire collection, information does not have a cycle, needs tuning when classifying records and it does not posses a structure. The limitations are:- There is no way to find topics inside the material or full text indexing.
- Searches can be long and complicated. There is usually a “middle man” that is the expert in searching, called the librarian.
- There is no permissions structure.
- Usually records are of the same type.
- Cannot be customized easily.
On the other side we have Active Filing, which came about with the Internet. The features we find in this side are: There is a structure (Navigational) and it can hold more than one like classifications, user permissions, etc. It is more dynamic, we can create cycles so that information goes from one state to another, Active-Passive-Archival. In this form we have a lot more interaction from people, sharing and collaborating on office documents. There is usually a full text index and you can search for information based on the structure. Classification is usually the key for handling document types and their retention. Ideally, with a retention scheme, the system can move back and forth information from one side to another. I like to view this system with the two types working in harmony, the passive archiving handling the bulk of data and heavy storage, and the active side handling the most used and active documents for quick retrieval. Its limitations are: 1- Not good for very big containers. 2- More complex to build.
Detail.
In passive mode, we use something like a bag of candies; we throw every candy in, and expect to find them in one place. So it is central by nature. These posses a problem for multiple locations, where you need to replicate the data. (The active scheme works well for combining central with distributed approaches). Working with our bag, requires deep knowledge on the tool we use for searching inside the bag. Why? Because the results might not give us exactly what we are looking for. Results can be extremely long and complicated to filter. You might not have the ability to change the resulting records in one shot; this again depends on the tool and the vendor. Some vendors like working with you, some do not even pay attention, so you have to foresee how much support you can get or buy.
In summary, libraries are a good tool only when the records and fields are static, or you do not have multiple types of documents.
There is a need to reform the way libraries are seen today so that they can include a more flexible approach, the active mode I described above. This way, we can integrate both into a “Live system”, and the end goal of having this methodology is to be able to cycle the information. This means that information gets created, is active for a period of time, but then it falls into a passive mode and if obsolete, then it should be deleted, but if it has some value, it should go into archival mode, and depending on the legal requirements for retention, you can store it for a number of years or for ever. Media used in big jukeboxes (used to handle the bulk of data) can survive for many years, some to even 100 years, probably more than what we will be around.
posted by Leonardo at 4:57 PM
![]()
![]()

0 Comments:
Post a Comment
<< Home