Classification & Structure Definition.
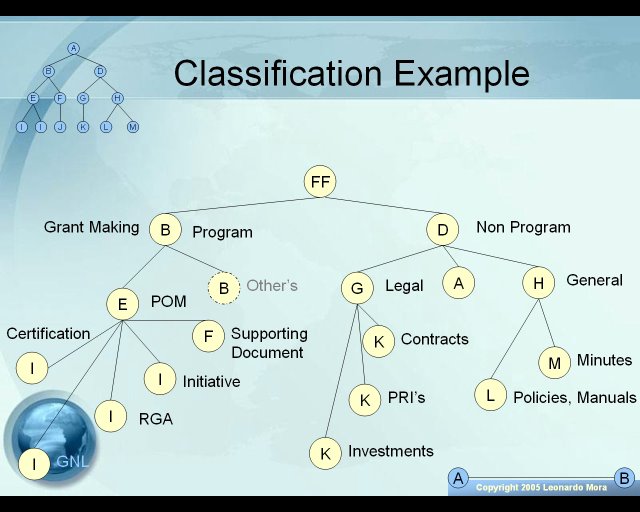
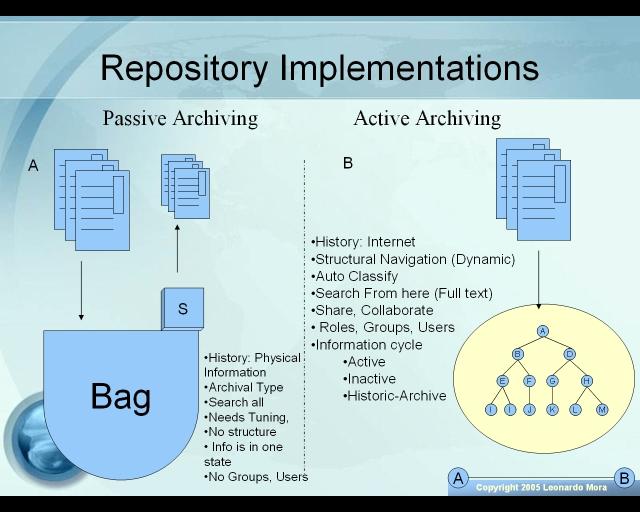
A classification tree is an structure where we divide information not from the unit or department where it comes from, but from the nature of the information, like contracts, purchase orders, letters, requests, financial reports, manuals, etc. Classifications are key because they can be used as the “controller” and to store aditional metadata concerning each type, meaning many of the rules legal and otherwise can be consolidated in it’s classification. Another aspect that can help you handle better documents is the flow of uploading them, or the number of steps needed to add a particular document. For Example, a Purchase order might follow a different path than the contract for legal services because it involves different sets of groups.
We call retention to the rules defined for each type of information that you want to store. For example, a contract might have the following rules:
• Remain active for 1 year.
• Remain passive for 3 months
• Archive 10 years.
• Cannot be deleted without approval.
• Modifications should be notified to owner.
Information can be treated as a living thing, having 3 main stages called Active, Passive, and Archive or Deletion stage. With this method, information can remain up to date, be more useful, and the overall organization can improve the performance of the system.
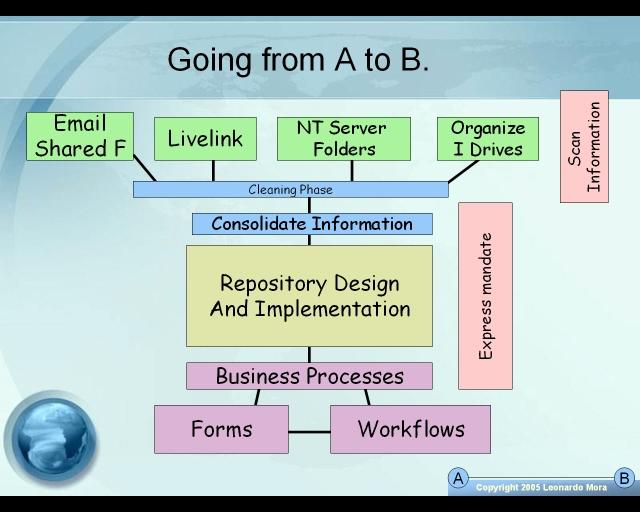
I believe classifications can serve tremendously in organizing information and making more useful a central database used as a repository, in parallel with a folder structure and a logical one. Classifying should give you as well a way to customize metadata (Additional fields) so that you can sort and retrieve more easily information. It gives you flexibility and power to configure your information in many different ways.
Again, the key is in your policies and procedures, making sure that a broad vision is set, and a clear mandate given so that teams can implement a complete repository.
posted by Leonardo at 2:39 PM
|
0 comments
![]()
![]()